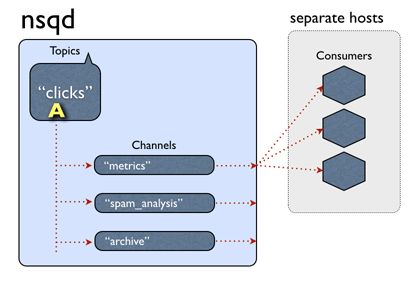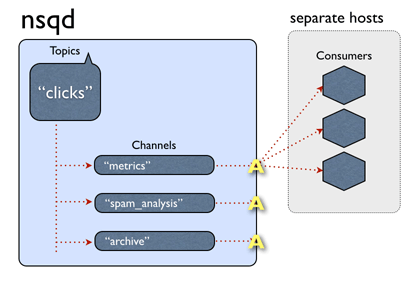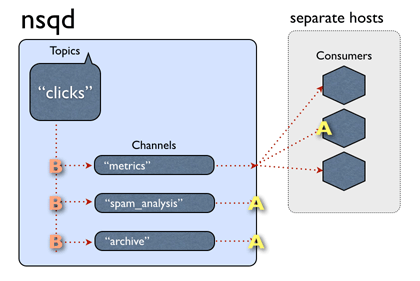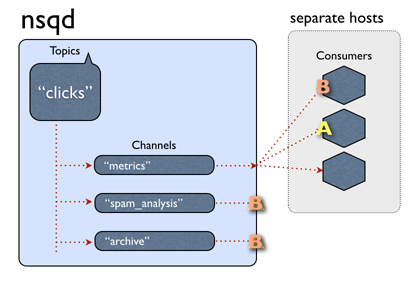
rabbitmq编译安装
乐果 发表于 2018 年 10 月 31 日
一、安装erlang
下载最新稳定版本,编译安装,例如:
http://erlang.org/download/otp_src_21.1.tar.gz
wget http://erlang.org/download/otp_src_21.1.tar.gz .
tar -xzvf otp_src_21.1.tar.gz
cd otp_src_21.1
./configure --prefix=/data/service/erlang/otp_21.1
sudo make
sudo make install
报错: configure: error: No curses library functions found configure: error: /home/xiao/download/otp_src_21.1/erts/configure failed for erts
缺少ncurses,安装sudo apt install libncurses5-dev
二、安装rabbitmq
下载最新稳定版本,编译安装,例如:
xz -d abbitmq-server-generic-unix-3.7.8.tar.xz
tar -xvf rabbitmq-server-generic-unix-3.7.8.tar
mv rabbitmq_server... /data/service/rabbitmq
cd /data/service/rabbitmq
./sbin/rabbitmq-server
//此时可能会报erl找不到
//这时需要把/data/service/erlang/otp_21.1/bin加入到环境变量PATH中去
//
//./sbin/rabbitmq-server -detached
报erl找不到,将erlang目录加入PATH: vim /etc/sudoers,修改:
……